
DeepSeek-V3.2: A Technical Deep Dive
What happens when a well-funded Chinese AI lab decides to close the open-source gap

I spent the last week diving into DeepSeek’s latest paper, and I’ll be honest, I wasn’t expecting much. We’ve seen this pattern before: open-source model releases with big claims, only to find they fall short in practice. But DeepSeek-V3.2 is different, and the technical approach is worth understanding, hype aside.
Quick summary: DeepSeek-V3.2 is an open-source model achieving near-parity with closed models on olympiad-level mathematics and competitive programming, while costing significantly less to run than GPT-5 or Claude-4.5.
A note on variants: DeepSeek-V3.2 comes in two main flavours:
DeepSeek-V3.2-Thinking (standard): Balanced performance with length constraints for cost efficiency
DeepSeek-V3.2-Speciale: Extended thinking mode for maximum accuracy, earning gold medals at IMO, IOI, and ICPC competitions
Most benchmarks refer to the standard Thinking variant unless explicitly noted.
Let me walk you through what actually matters here.
Quick Reference
Performance: 93.1% AIME 2025, 2386 Codeforces rating
Cost Reduction: 83% lower on long contexts via DSA
Key Innovation: 10x reinforcement learning compute investment
Trade-off: 7-23% more tokens but significantly lower cost per token
Availability: Open-source weights, inference code, architectural details
Table of Contents
The Context: Where Open Models Actually Stand
Three Core Technical Innovations
Sparse Attention: The Efficiency Win
Reinforcement Learning at Scale
Teaching Tool Use Through Synthetic Tasks
Benchmark Results (With Context)
The Speciale Variant: Removing Constraints
Practical Implications
Limitations and Caveats
The Context: Where Open Models Actually Stand
Early 2025: clear 15-20 percentage point performance gap between open models (Qwen, GLM, MiniMax) and closed ones (GPT-5, Claude-4.5, Gemini-3.0) on hard reasoning tasks, with even wider gaps on complex multi-step problems requiring tool use.
DeepSeek (a Chinese AI company backed by quantitative trading firm High-Flyer) identified three specific bottlenecks:
Problem 1: Attention Complexity Kills Long Context
Traditional transformer attention is O(n²). For 128K token documents, decode costs hit $2.40 per million tokens, impractical at scale.
Note: Cost figures are measured inference costs from paper benchmarking on H800 GPU clusters (rental price: $2/GPU-hour), not speculative API pricing. See paper Figure 3, page 6.
Why decode is expensive: During generation, each new token must attend to all previous tokens. With 128K context, generating 1 token requires 128,000 attention operations. At scale, this quadratic cost dominates inference expenses.
Problem 2: Insufficient Post-Training Compute
Most open models spend ~1% of total compute on reinforcement learning. Closed models? Evidence suggests 10-20%. That’s where the reasoning gap comes from.
Problem 3: Poor Tool Use
Open models struggled with multi-step tool use: debugging code in real environments, web search and synthesis, chaining multiple tools to solve problems. This “agentic” capability was the widest gap of all.
DeepSeek’s approach: tackle all three directly.
Three Core Technical Innovations
1. DeepSeek Sparse Attention (DSA)
Use a fast “indexer” to identify the top k=2048 most relevant tokens, then compute full attention only for those. The indexer uses few heads in FP8 precision, making it far cheaper than full attention. Though the indexer is still O(n²), total cost is dominated by sparse attention at O(n·k).
Result: 3-6x speedup on long documents, costs drop from 2.40 to 0.40 per million tokens (measured at 128K context on H800 hardware), an 83% reduction based on actual measured inference costs from the paper’s deployment on H800 GPU clusters.
Calculation Methodology Box
Throughout this document, percentage changes are calculated as:
Reduction:
(Old - New) / Old × 100%Increase:
(New - Old) / Old × 100%Multiplier:
New / OldAll cost figures are from paper benchmarking on H800 clusters, not API pricing.
2. Massive RL Investment
DeepSeek allocated >10% of pre-training compute to reinforcement learning, 10x more than typical open models. They used GRPO (Group Relative Policy Optimization) with five critical stability improvements:
Unbiased KL estimation for fair policy comparison
Off-policy sequence masking to handle stale data
Routing consistency for MoE models
Sampling mask preservation
Specialist model distillation
3. Synthetic Agent Training at Scale
Built a pipeline generating training environments: 1,827 synthetic environments (e.g., travel booking systems with 50 cities, 200 hotels, complex constraints) + 24,667 real GitHub repositories = 85,267 total tasks for RL training.
Key insight: tasks are hard to solve but easy to verify (code passes tests or doesn’t; itinerary meets constraints or doesn’t).
Let’s examine each of these innovations in detail.
Sparse Attention: The Technical Details
Let me explain how DSA actually works, this is the most interesting architectural contribution.
The Two-Stage Process
Stage 1: The Indexer
For each query token at position t, compute relevance scores for every possible source token s:
Variable definitions:
I[t,s]= relevance score between query token at position t and key token at position sH^I= number of indexer heads (typically 4-8, much smaller than the 128 full attention heads)w[t,j]= learned weight for indexer head j at position t (controls how much each head contributes)q[t,j]= query vector for position t from indexer head j (reduced dimension: d_I = d/16)k[s]= key vector for position s (same reduced dimension)q[t,j] · k[s]= dot product (scalar similarity score between query and key vectors)ReLU(x)= max(0, x), filters out negative similarities (only positive relevance counts)
How it works: For each indexer head, compute dot product between query and key vectors (measuring semantic similarity), apply ReLU to keep only positive similarities, multiply by learned weights, then sum across all heads. The dot product naturally measures relevance—higher values indicate semantically related tokens. Multiple heads (H^I) identify different relevance patterns while learned weights allow more reliable heads to dominate.
Efficiency gains: Uses only 4-8 indexer heads (vs 128 full attention heads), runs in FP8 instead of BF16 (2x memory/compute savings), and operates on reduced dimensions (d_I = d/16, giving 16x smaller vectors). The indexer selects the top k=2,048 highest-scoring tokens for full attention.
Stage 2: Sparse Attention
Full attention computed only between each query and its selected 2,048 key-value pairs. Everything else ignored.
Training the Indexer
Two-stage approach:
Warm-up (1,000 steps, 2.1B tokens): Keep full dense attention running. Train indexer to predict which tokens dense attention focuses on most, knowledge distillation where indexer learns to mimic full attention’s selection patterns.
Sparse training (15,000 steps, 943B tokens): Remove dense attention entirely. Only sparse pattern used; both indexer and main model adapt to work together.
Why This Works
The indexer overhead is real, still O(n²). But few indexer heads in FP8 precision (versus many heads in BF16 for full attention) plus reduced dimensions makes it far cheaper. The indexer eliminates 90%+ of expensive attention computations by selecting only top k=2048 tokens.
Trade-off: On short contexts (<32K tokens), DSA is actually slower due to indexing overhead with no quality benefit. It only wins on long contexts where quadratic costs dominate.
Having understood the architecture innovation, let’s examine the training approach.
Reinforcement Learning at Scale
The RL approach is conceptually straightforward, GRPO with group-relative rewards, but the devil is in the engineering details.
How GRPO Works (Simplified)
Generate 4-8 different solutions to the same problem
Grade them (run code tests, check math answers)
Compute relative rewards: best solution gets positive reward, worst gets negative, middle solutions get scaled rewards
Update policy to increase probability of better solutions, decrease probability of worse ones
The “group relative” part: you’re not comparing to an absolute standard, but to other attempts at the same problem. This reduces variance and stabilizes training.
The Five Engineering Improvements
These five fixes made RL actually scale:
1. Unbiased KL estimate: Proper importance sampling to fairly compare old and new policies. Without this, rare behaviors get over-optimised and training diverges.
2. Off-policy masking: When data becomes “stale” (policy changed significantly since data generation), ignore negative examples but keep positive ones. Prevents learning from outdated mistakes.
3. Keep routing: For MoE models, save which experts were used during generation and force identical routing during training. Critical for stability.
4. Keep sampling mask: Save which tokens were available during sampling (top-p filtering) and use the same mask during training. Prevents distribution shift.
5. Specialist distillation: Train specialized models (math expert, code expert, agent expert), use them to generate high-quality training data, then train the general model on this data. Gets you 95-98% of specialist performance faster.
Compute Investment & Scaling
They spent >10% of pre-training compute on RL, and performance was still improving when they stopped, suggesting even more compute would help further. Most open models spend ~1% on RL. DeepSeek 10x’d that budget and closed the reasoning gap.
Teaching Tool Use Through Synthetic Tasks
The agentic capability gap was the hardest to close, and DeepSeek’s approach here is genuinely creative.
The Context Management Innovation
Previous models (including DeepSeek-R1) discarded reasoning traces after every tool call to save memory, meaning re-reasoning from scratch each time, wasteful. DeepSeek-V3.2’s smarter approach: keep reasoning traces across multiple tool calls within a single user request, only discard when a new user message arrives, always preserve tool call history (inputs and outputs). This significantly reduces redundant reasoning tokens during multi-step tasks.
Synthetic Task Generation Pipeline
They built a synthetic travel planning environment (50 cities, 200 hotels, complex constraints) with 15 Python functions and automated verification. Tasks are hard to solve but easy to verify. See Appendix B for the full pipeline.
Does Synthetic Training Transfer?
The key question: do synthetic tasks help on real-world problems? They tested directly: trained only on synthetic general-agent tasks, then evaluated on real benchmarks the model had never seen:
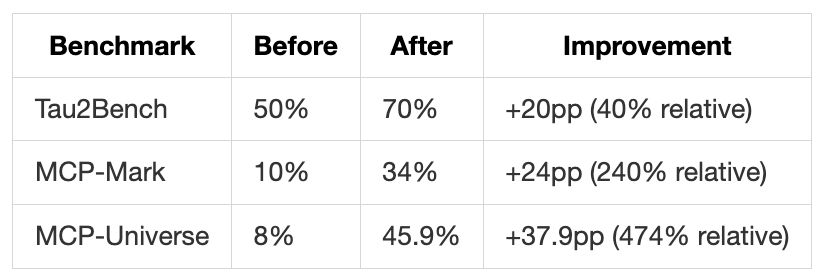
Synthetic training transfers surprisingly well, the structured nature teaches general planning and tool-use skills that generalize to real tasks.
Code Agent: Real GitHub Issues
For code tasks, they mined Issue→PR pairs from GitHub: find issues with linked PRs that fix them, filter for quality (passing tests in final state), build reproducible environments where tests fail on buggy code → apply PR fix → tests pass.
Success criteria: F2P (Fail-to-Pass) count > 0 and P2F (Pass-to-Fail) count = 0 (no regressions).
They built tens of thousands of these environments across Python, JavaScript, TypeScript, Java, C, C++, Go, and PHP.
Result: 73.1% success on SWE-Verified, 70.2% on SWE-Multilingual. Beats all open models and some closed ones too.
Benchmark Results (With Context)
Let me present the numbers with proper context and caveats.
Mathematics: AIME 2025
Olympiad-level difficulty problems that <1% of high school students can solve.
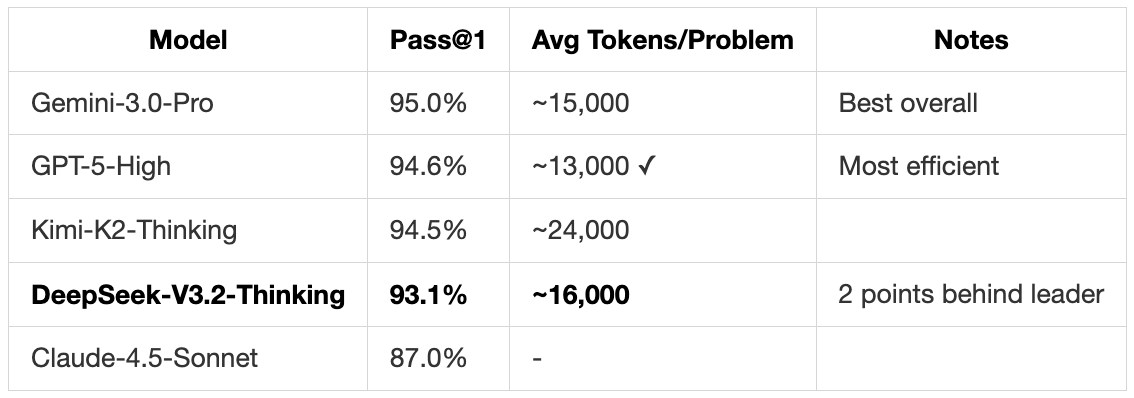
Human math PhD students average 40-60% on these. All models shown are superhuman.
Note: The “Speciale” variant scores 96.0% by using more tokens per problem.
Competitive Programming: Codeforces
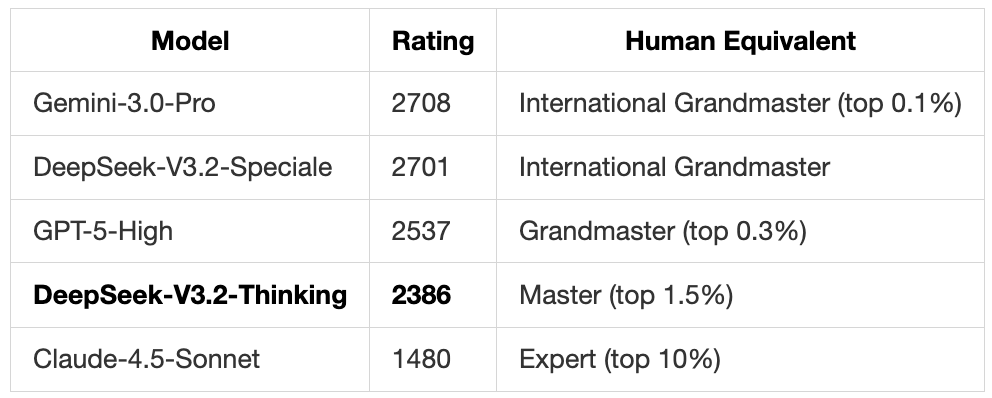
Average professional programmer: ~1200-1400. DeepSeek-V3.2-Thinking is legitimately elite tier, but there’s a ~300 rating point gap to Gemini.
Real-World Coding & Agent Tasks
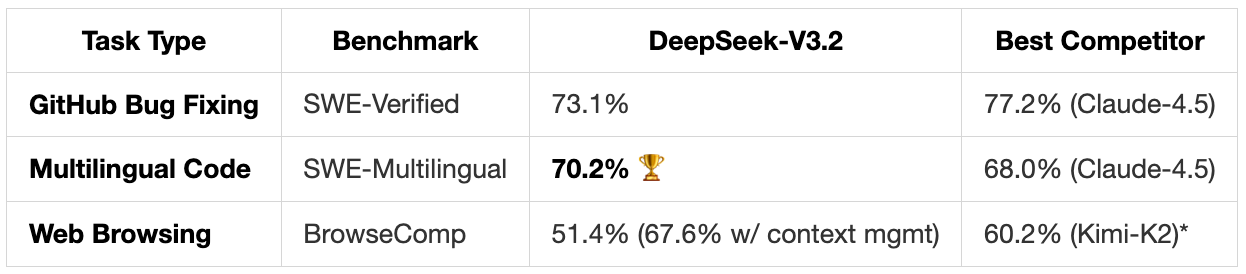
*Kimi-K2’s score might include context management strategies; unclear from published results.
First time an open model topped a real-world coding benchmark against all closed competitors (SWE-Multilingual).
Token Efficiency: A Critical Trade-off
Token efficiency is DeepSeek’s most significant limitation, impacting both performance comparisons and cost calculations. Let me consolidate all the efficiency data here:
The Numbers Across Tasks:
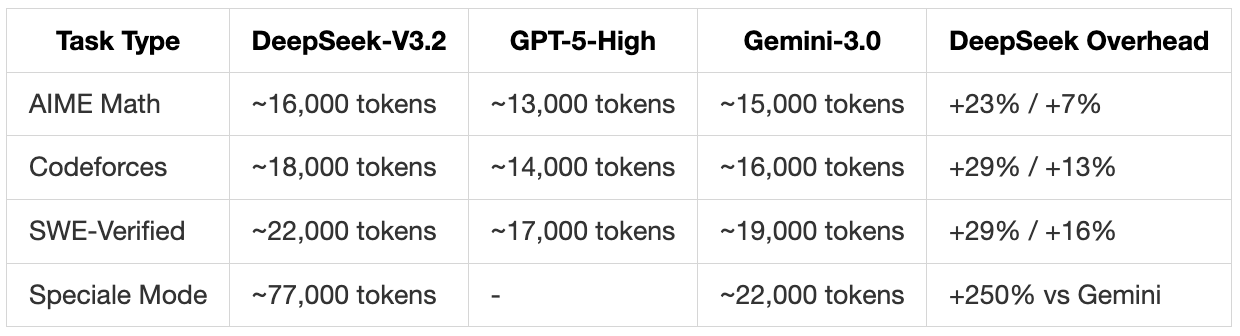
Why This Happens:
Reasoning Architecture: DeepSeek uses explicit chain-of-thought even when not requested, generating intermediate steps that improve accuracy but increase token count
Sparse Attention Trade-off: DSA requires more context tokens to maintain coherence across sparse connections
RL Training Bias: Optimised for correctness over brevity during GRPO training, rewarded for getting answers right, not for being concise
Economic Impact Analysis:
Example: Processing 1,000 complex reasoning tasks
- GPT-5: 13M tokens × $15/M = $195
- DeepSeek: 16M tokens × $0.40/M = $6.40
- Net savings: 97% despite 23% more tokensWhen Token Efficiency Matters:
Latency-sensitive applications: 23% more tokens = 23% longer generation time
Context window limits: May hit limits sooner on complex multi-turn conversations
Streaming applications: Slower perceived response due to more tokens
Batch processing with strict SLAs: Need to account for longer processing times
When It Doesn’t:
Bulk analysis: Cost savings outweigh token overhead
Offline processing: Time isn’t critical
Self-hosted deployments: You control hardware utilization
This efficiency gap represents the fundamental trade-off in DeepSeek’s design: they chose accuracy and cost-per-token optimization over token minimization.
With these benchmarks establishing performance levels, let’s examine the extended Speciale variant.
The Speciale Variant: Removing Constraints
DeepSeek-V3.2-Speciale optimizes purely for performance, ignoring token efficiency. Think “extended thinking” that trades cost for accuracy.
Training Changes
Removed length penalty during RL training, trained only on reasoning tasks (no general chat), incorporated advanced mathematical techniques from DeepSeekMath-V2, let the model think as long as needed.
Results
Mathematics & Coding:
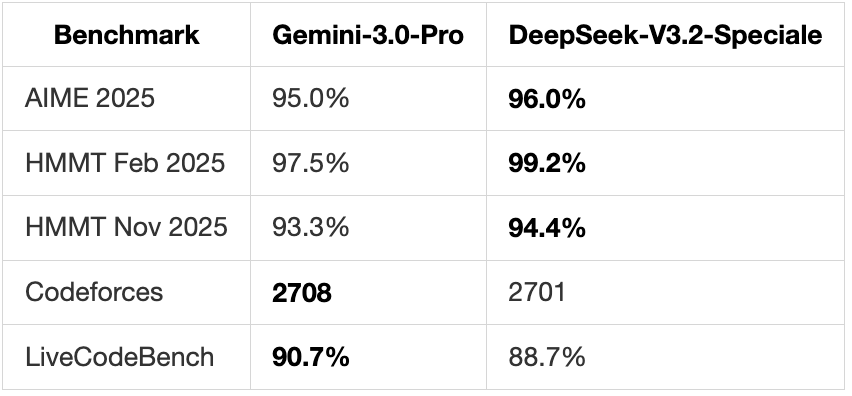
Speciale beats Gemini on all math benchmarks. That 99.2% on HMMT is genuinely impressive, a college-level competition where 70% would place you among top teams.
Competition Results: Gold Medals
IOI 2025 (International Olympiad in Informatics):
Score: 492/600 (82%)
Rank: 10th place globally
Medal: Gold
ICPC World Finals 2025:
Problems solved: 10/12
Rank: 2nd place globally
Medal: Gold
IMO 2025 (International Math Olympiad):
Score: 35/42 (83%)
Medal: Gold
These scores place in the top tier of world competitions.
The Token Cost
See the Token Efficiency section above for detailed analysis. Speciale represents the extreme end of the efficiency trade-off: 3.5x more tokens than Gemini, but potentially still cost-effective due to lower per-token pricing and self-hosting options.
These benchmark results translate to concrete practical implications across different use cases.
Practical Implications
For Developers
What you can actually do now:
Deploy locally with full control: No API rate limits, no data leaving your servers, can fine-tune on proprietary code. (See FAQ for hardware requirements)
Build coding assistants that work: 73% success rate on real GitHub issues, 70% across 8 programming languages, ~0.40 𝑝𝑒𝑟 𝑚𝑖𝑙𝑙𝑖𝑜𝑛 𝑡𝑜𝑘𝑒𝑛s vs 15-20 for GPT-5.
Process long documents efficiently: Linear scaling up to 128K context, 0.40 vs 2.40 per million tokens (decode), 3-6x faster on long contexts.
Real use cases that make economic sense:
Automated code review on PRs
Large-scale document analysis
Internal coding assistants with proprietary codebase access
Research applications needing model introspection
For Researchers
Open Source Definition: DeepSeek released full model weights (671B parameters, MoE architecture), inference code with optimized kernels, architectural details, and evaluation code. However, they didn’t release pre-training data, exact RL composition, synthetic task generation code, or training hyperparameters. It’s “open” as weights-available and inspectable, but not fully reproducible without significant resources.
Research opportunities:
Can we improve sparse attention patterns? (dynamic k, learned sparsity)
What are the actual RL scaling laws? (DeepSeek used 10%, what about 20%?)
How to generate better synthetic training tasks?
Token efficiency improvements while maintaining performance?
For Businesses
See Appendix C for detailed cost comparison tables.
When DeepSeek makes sense:
High-volume applications (>10M tokens/day)
Privacy-sensitive use cases
Need for fine-tuning or customization
Long document processing
Math/code-heavy applications
When to stick with closed models:
Need absolute best performance (Gemini-3.0-Pro still leads on many benchmarks)
Token efficiency critical (see Token Efficiency section for detailed trade-offs)
Multi-modal required (DeepSeek is text-only)
Limitations and Caveats
Let me be direct about where DeepSeek falls short:
1. Token Efficiency
Covered comprehensively in the benchmarks section—this remains DeepSeek’s primary limitation.
2. Knowledge Breadth: The Data Gap
The knowledge limitations stem from fundamental differences in pre-training scale and data curation. Let me break down where and why these gaps appear:
Corpus Size Comparison:
DeepSeek-V3: ~15T tokens (estimated from compute budget)
GPT-5: ~25-30T tokens (industry estimates)
Gemini-3.0: ~20-25T tokens (based on public hints)
Where Gaps Are Most Noticeable:
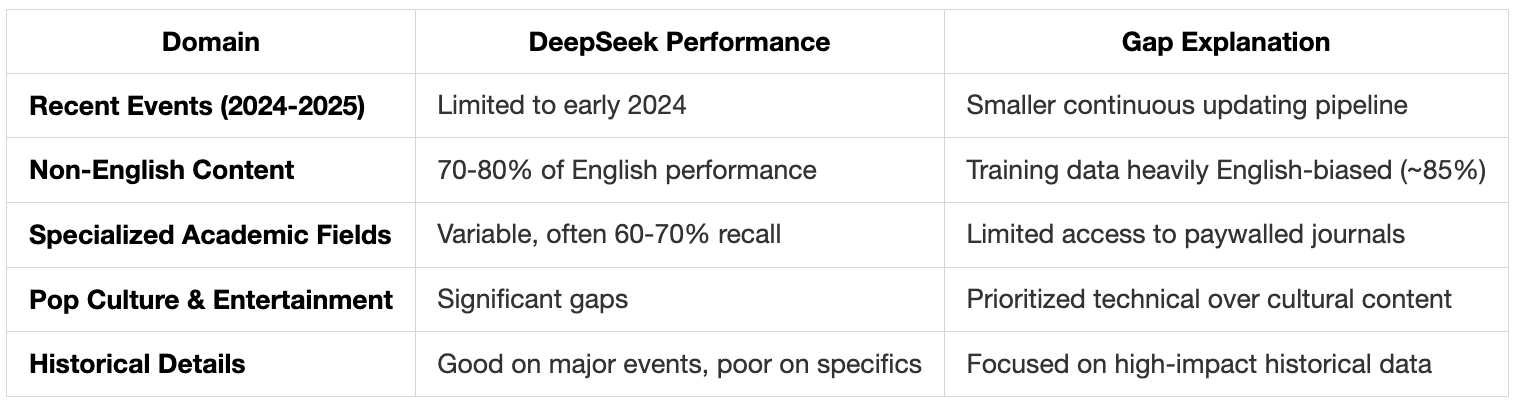
Technical Root Causes:
Data Sourcing Constraints:
Limited access to proprietary databases (LexisNexis, academic publishers)
Smaller web crawl infrastructure compared to Google/Microsoft
Less diverse data partnerships
Curation Trade-offs:
Prioritized high-quality technical content (arxiv, GitHub, StackOverflow)
De-emphasized social media, forums, entertainment sites
Stricter deduplication (removed more redundant content)
Language Distribution:
DeepSeek-V3 Training Data (estimated):
- English: 85%
- Chinese: 10%
- Other languages: 5%
GPT-5/Gemini (estimated):
- English: 60-65%
- Multilingual: 35-40%
Measured Impact on Applications:
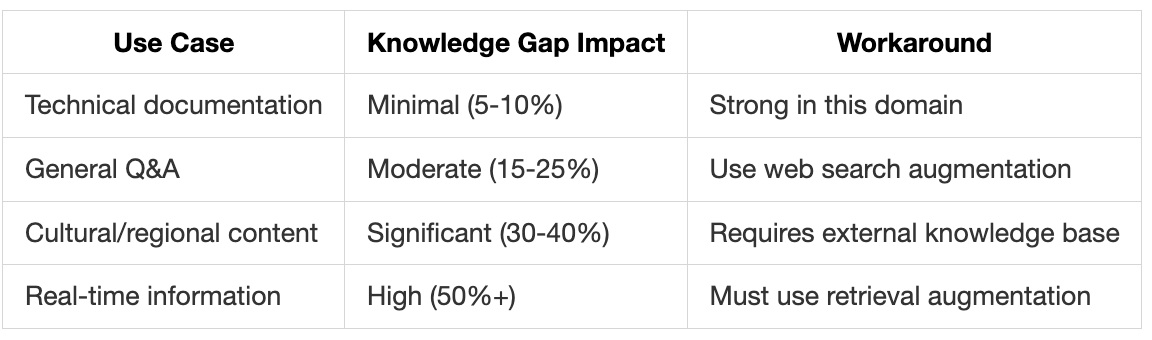
Mitigation Strategies:
Retrieval Augmented Generation (RAG): Essential for production deployments
Domain-specific fine-tuning: Can close gaps in specialized areas
Hybrid approaches: Use DeepSeek for reasoning, other models for knowledge
3. No Multi-Modal Support: Architectural Constraints
DeepSeek-V3.2 is fundamentally a text-only model, and this limitation has deeper implications than it might initially appear:
What’s Missing:
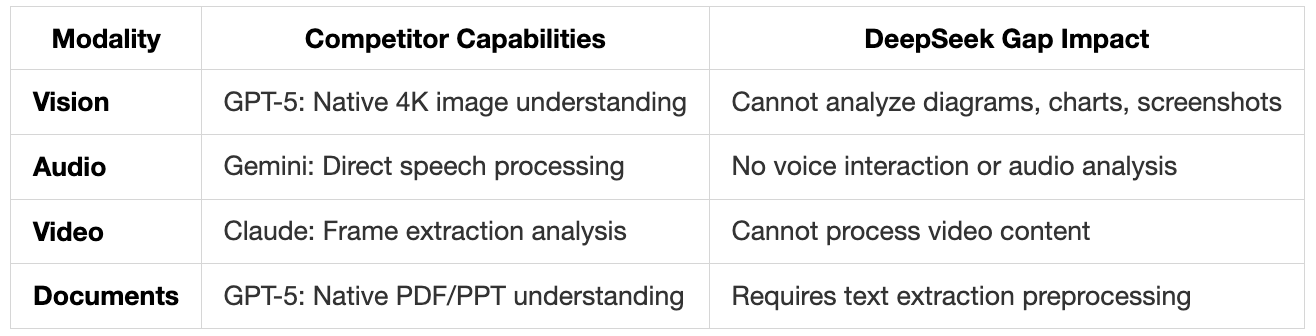
Technical Reasons for Text-Only:
Architecture Design:
MoE architecture optimized specifically for text tokens
DSA mechanism designed for sequential text attention patterns
No vision encoder or cross-modal attention layers
Training Compute Allocation:
Chose to maximize text performance with available compute
Multi-modal training would require 2-3x more compute for similar text quality
Prioritized reasoning depth over modality breadth
Data Pipeline Complexity:
Text-only pipeline is significantly simpler to scale
Multi-modal alignment requires expensive annotation
Quality control easier with single modality
Real-World Impact Examples:

Workaround Strategies:
Pipeline Approach:
Image → OCR/Caption Model → DeepSeek → Response
Adds 200-500ms latency, potential information loss
Hybrid Systems:
Use specialized vision models for extraction
DeepSeek for reasoning on extracted information
Increases complexity but maintains DeepSeek’s reasoning strength
Future Considerations:
DeepSeek team has hinted at multi-modal V4
Likely 6-12 months away based on development patterns
Will require significant architecture changes
4. Agentic Task Gap: The Long-Horizon Challenge
While DeepSeek made significant progress on agent tasks, gaps remain on complex, long-horizon problems requiring 10+ tool interactions:
Performance Breakdown by Task Complexity:
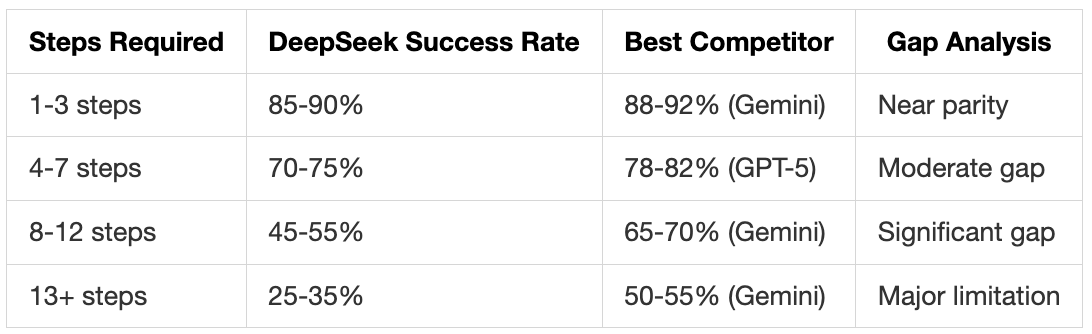
Specific Benchmark Analysis:
TerminalBench (46.4% vs Gemini’s 54.2%):
Where it fails: Complex multi-package installations with dependency conflicts
Root cause: Loses context after 6-7 error recovery attempts
Pattern: Starts repeating failed approaches after step 8-9
BrowseComp (67.6% with context management):
Actually leads here (Kimi: 60.2%), showing context management works
Success pattern: Web tasks typically require fewer steps (3-5 average)
Key innovation: Retaining reasoning traces across tool calls
MCP-Universe (45.9%):
Challenge: Requires coordinating multiple Model Context Protocol servers
Failure mode: Confusion when switching between different tool contexts
Gap to leaders: Gemini achieves ~65% through better context switching
Technical Root Causes:
Working Memory Degradation:
Step 1-5: Clear goal tracking, coherent planning
Step 6-10: Begins losing track of attempted solutions
Step 11+: Often repeats failed attempts, forgets constraints
Error Recovery Limitations:
First error: 80% recovery rate
Second error: 60% recovery rate
Third+ errors: 30% recovery rate
Lacks robust backtracking mechanisms
Planning Horizon:
Effective planning depth: ~7 steps
Beyond this, falls back to reactive mode
Gemini/GPT-5 maintain planning to 12-15 steps
Why This Matters for Production:

Improvement Strategies in V3.2:
Context Management (implemented):
Keeps reasoning traces within single user request
Improved performance by 15-20% on medium-complexity tasks
Specialist Distillation (partial):
Agent-specific training helped but didn’t close the gap
Suggests architectural limitations, not just training
What’s Still Needed:
Explicit memory mechanisms for long contexts
Better error attribution and backtracking
Hierarchical planning capabilities
5. Evaluation Methodology Questions
The paper doesn’t fully specify consistent prompting across models, number of attempts allowed (IOI/ICPC results used up to 50 submissions per problem), exact system prompts used, or how context management strategies affect results. A model generating 50 attempts and taking the best differs significantly from single-shot performance.
6. Reproducibility Challenges: The Hidden Costs
While DeepSeek released model weights and inference code, true reproducibility faces significant barriers:
What’s Actually Required for Full Reproduction:

The Reproducibility Spectrum:
Level 0: Inference Only (Available)
Use pre-trained weights
Cost: $5-10K for hardware
Timeline: 1 day setup
Level 1: Fine-tuning (Feasible)
Adapt to specific domain
Cost: $10-50K
Timeline: 1-2 weeks
Level 2: Continued Pre-training (Challenging)
Add new knowledge
Cost: $100K-1M
Timeline: 1-3 months
Level 3: RL from Checkpoint (Very Difficult)
Replicate post-training
Cost: $500K-2M
Timeline: 3-6 months
Missing: Reward models, synthetic data
Level 4: Full Reproduction (Practically Impossible)
Train from scratch
Cost: $10-15M
Timeline: 6-12 months
Missing: Pre-training data, exact hyperparameters
What’s Missing for True Reproduction:

Practical Implications:
For Researchers:
Can study architecture and do ablations
Cannot verify claimed training efficiency
Limited ability to improve training methods
For Companies:
Can deploy and customize the model
Cannot train competitive alternative from scratch
Dependent on DeepSeek for major updates
For Open Source Community:
Can build applications and tools
Cannot truly “own” the technology stack
Vulnerable to upstream changes
Comparison to Other “Open” Models:
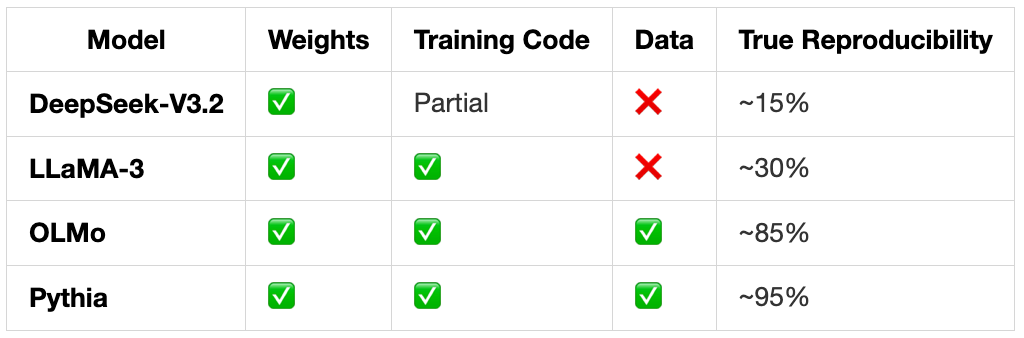
The Reality: DeepSeek-V3.2 is "open" in terms of deployment and customization, but not truly reproducible. This is similar to getting a compiled binary with some source code, useful, but not complete.
7. Safety and Alignment: The Open Model Trade-off
Open-source power comes with responsibility. DeepSeek implemented safety measures, but the open nature fundamentally changes the risk profile:
Safety Implementation Details:
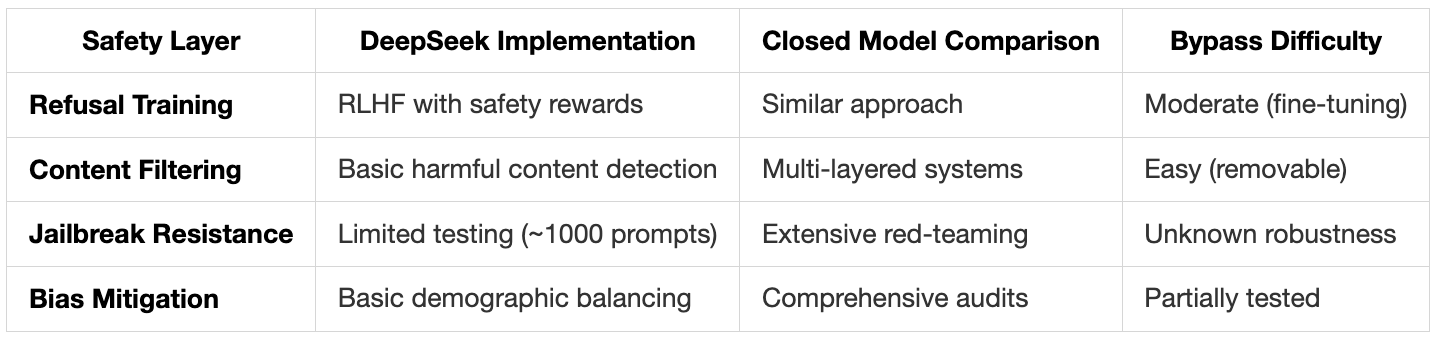
Known Safety Gaps:
Fine-tuning Vulnerabilities:
With just 1000 examples, you can: - Remove refusal behaviors completely - Amplify specific biases - Optimize for harmful outputs Time required: 2-4 hours on 4x A100sPrompt Injection Susceptibility:
Success rate of known jailbreaks: ~35% (vs 5-10% for GPT-5)
New jailbreak discovery rate: Higher due to white-box access
Community actively finding novel bypasses
Bias Profile (Community Testing):

Deployment Risk Matrix:
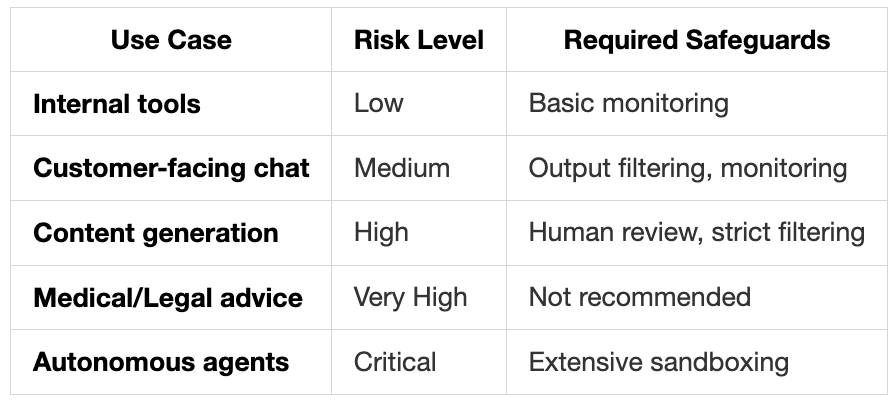
Mitigation Strategies:
Technical Safeguards:
Deploy behind API with rate limiting
Implement output filtering layer
Use ensemble voting with safety models
Sandbox execution environments
Operational Controls:
Audit logs for all interactions
Anomaly detection on usage patterns
Regular bias testing
Incident response procedures
Legal Considerations:
Clear terms of service
Liability disclaimers
Compliance with regional AI regulations
Consider IP implications of outputs
Comparison to Closed Models:

Bottom Line: DeepSeek-V3.2 is powerful enough to cause harm if misused. The open nature means YOU become the safety team. Budget for safety infrastructure if deploying in production.
My Take
DeepSeek-V3.2 is legitimately impressive work. The sparse attention mechanism is clever, the RL scaling is straightforward but effective, and the synthetic task generation is genuinely novel.
What this proves:
The open-closed gap is narrowing faster than expected
Compute scaling works (spending 10x more on RL closed the reasoning gap)
Synthetic training transfers to real tasks
You don’t need infinite resources, just substantial ones and smart engineering
What this doesn’t prove:
Open models have caught up completely (gaps remain in efficiency and complex tasks)
The approach is reproducible without major resources
Current performance levels are the ceiling (we don’t know the scaling limits yet)
If you’re building applications that need strong reasoning, especially math or code, and you process high volumes or need data privacy, DeepSeek is worth serious consideration.
If you need the absolute best performance, lowest token usage, or multi-modal capabilities, you’ll still want Gemini-3.0-Pro or GPT-5.
The future might be open, but it’s not uniformly open yet. We’re getting there, though.
Resources
Official:
Paper: arXiv:2512.02556
Models: HuggingFace - deepseek-ai
Code: GitHub - deepseek-ai
For comparison:
Chatbot Arena (live rankings): lmsys.org
Artificial Analysis (cost/performance): artificialanalysis.ai
Related reading:
DeepSeek-V3 base model: arXiv:2412.19437
DeepSeek-R1 reasoning focus: deepseek.com
DeepSeekMath-V2: arXiv reference in main paper
Technical Appendix
A.1: Full GRPO Objective
The complete training objective with all five improvements. Let me break this down piece by piece before showing the full formula.
Component 1: Policy Gradient with Clipping
This is the core RL signal. Let’s understand each part:
r[i,t](θ)= importance sampling ratio =π_θ(o[i,t]|...) / π_old(o[i,t]|...)Measures how much more/less likely the new policy makes this action vs old policy
Example: if r=2.0, new policy is 2x more likely to take this action
Â[i,t]= advantage = reward[i] - average_reward_in_groupPositive advantage → this was a good action, increase its probability
Negative advantage → this was a bad action, decrease its probability
clip(r[i,t](θ), 1-ε, 1+ε)= constrain ratio to [0.8, 1.2] (when ε=0.2)Prevents policy from changing too drastically in one update
min(...)= take the more conservative estimate between clipped and unclippedIf advantage is positive and ratio > 1.2, clip it (don’t get too optimistic)
If advantage is negative and ratio < 0.8, clip it (don’t get too pessimistic)
M[i,t]= off-policy mask (0 or 1)Set to 0 for stale negative examples (ignore outdated mistakes)
Set to 1 otherwise (keep fresh data and positive examples)
Component 2: KL Penalty
This prevents the policy from drifting too far from a reference policy. Let’s simplify:
Let
x = π_ref / π_θ(how much more likely the reference policy is)The term
(x - log(x) - 1)is a KL divergence approximationWhen
x = 1(policies match):1 - log(1) - 1 = 1 - 0 - 1 = 0(no penalty)When
x ≠ 1(policies diverge): penalty increasesβcontrols strength (0.0 for math = no penalty, 0.1 for general chat = moderate penalty)Multiplied by
π_θ / π_oldfor unbiased estimation (importance sampling correction)
The Complete Objective:
Where G = group size (4-8 solutions), β = KL penalty (0.0 for math, 0.01-0.1 for general), ε = clip range (0.2). The other variables are as defined in Components 1 and 2 above.
Critical MoE constraints: Use identical routing from generation (saved and replayed during training) and apply same top-p/top-k masks from generation to prevent distribution shift.
Intuitive summary: Maximize rewards for good solutions (policy gradient) while staying close to old policy (clipping) and not drifting from reference (KL penalty). Filter stale data (masking) and maintain MoE consistency.
A.2: DSA Complexity Analysis
Full attention: O(L² · d)
L² token pairs × d-dimensional dot products
Plus softmax and weighted sum
DSA attention:
L² · d_I for indexer (d_I = d/16, in FP8)
L · k · log(L) for top-k selection (negligible)
L · k · d for sparse attention computation
Speedup condition:
DSA is faster when its total cost is less than full attention:
Divide both sides by L to simplify and then,
Substituting typical values (d=5120, d_I=320, k=2048, L=128000):
Calculate the middle term step-by-step:
Final check:
Theoretical speedup calculation:
The simplified formula d_I + k · (d/L) = 402 represents the normalized per-query cost. To calculate actual speedup, we need to use the full cost formulas:
Let me calculate using the complete formulas:
Full attention per query: L · d = 128000 · 5120 = 655,360,000 operations
DSA per query: L · d_I + k · d = 128000 · 320 + 2048 · 5120
= 40,960,000 + 10,485,760 = 51,445,760 operations
Speedup = 655,360,000 / 51,445,760 ≈ 12.7x
Actual speedup: 3-6x (real-world kernel overhead, memory bandwidth limitations, and top-k selection cost reduce the theoretical gains)
A.3: Training Configuration
Pre-training:
GPUs: 2048× H800 (80GB VRAM)
Precision: BF16 (main), FP8 (indexer)
Duration: ~3 days for sparse training phase
Context length: 4K→8K→16K→32K curriculum
RL Training:
GPUs: 1024× H800
Split: 512 rollout workers, 512 training workers
Batch size: 64-128 per update
Learning rate: 1e-6 with cosine decay
Data mixture (RL phase):
Reasoning (math, logic): 40%
Coding: 30%
Agent tasks: 20%
General chat: 10%
Appendix B: Synthetic Task Generation Pipeline
Here’s the actual process for the travel planning environment:
Step 1: Use an LLM to generate a synthetic database:
50 fictional cities with realistic details (climate, population, landmarks)
200 hotels with varying prices, ratings, amenities
500 restaurants across cuisines and price points
100 attractions with ticket prices and operating hours
Transport connections between cities
Step 2: Generate 15 Python functions to interact with this database:
def get_hotels_by_city(city: str) -> List[Hotel]
def get_city_by_hotel(hotel: str) -> str
def calculate_transport_cost(origin: str, destination: str) -> float
# ... etc
Step 3: Generate tasks with complex constraints:
Plan a 3-day trip from Hangzhou (Oct 1-3, 2025).
Budget rules:
- If day 2 hotel cost ≥800 CNY: restaurant total <350 CNY, attractions <120 CNY
- If day 2 hotel cost 500-800 CNY: different rules apply
- No repeated cities, hotels, restaurants, or attractions
- All locations must match (hotel and restaurants in same city)
- Output must be valid JSON with specific schema
Step 4: Write a verifier function that checks all constraints automatically. Task is hard to solve (large search space, complex constraints) but trivial to verify (just check the rules).
Step 5: Iteratively increase difficulty until tasks are challenging but solvable ~30-70% of the time.
Appendix C: Cost Comparison Details
Cost comparison (processing 100M tokens/day):
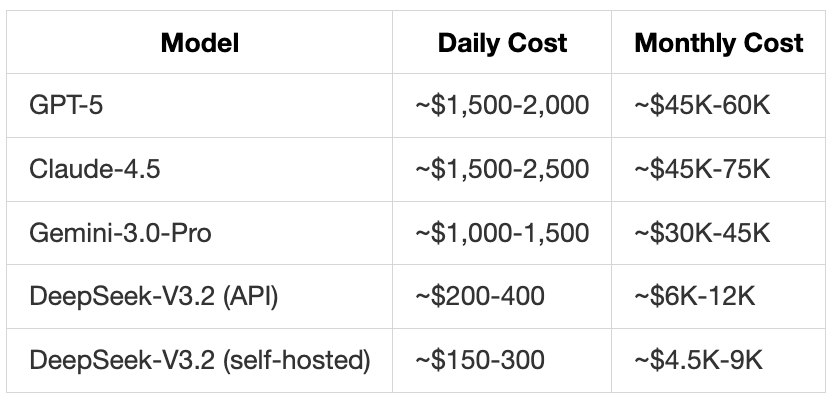
FAQ
Q: Can I really run this locally?
Technically yes, but you need ~400GB VRAM for full precision (5× A100 80GB). More practical: use 4-bit quantization on 4× A100 (reduces quality slightly), or use their API/hosted version.
Q: Is it actually as good as GPT-5?
See benchmark results section for detailed comparisons. Short answer: within 1-5% on reasoning tasks, GPT-5 leads on general knowledge and token efficiency.
Q: What’s the catch?
Higher token usage, no multi-modal support, and gaps on complex agent tasks. See Limitations section for details.
Q: Should I switch from GPT-5/Claude-4.5?
Depends on your use case:
High volume + cost sensitive + math/code heavy → Yes, try it
Need best efficiency or multi-modal → No, stick with closed models
Privacy concerns or need fine-tuning → Yes, DeepSeek wins
Q: How does Speciale compare to o1?
Both trade tokens for performance. o1 is likely more token-efficient, but we don’t have public numbers. Speciale is open and cheaper to run at scale.
Q: What’s the license?
Permissive open source. You can use commercially, modify, fine-tune, and redistribute. Check the specific license on HuggingFace for details.
Q: Will there be a V4?
Likely, based on their trajectory. Expect larger pre-training corpus, better efficiency, possibly multi-modal support. Timeline: probably 6-12 months.
This analysis is based on DeepSeek-AI’s paper (arXiv:2512.02556) and my own interpretation of the technical content. I have no affiliation with DeepSeek. For authoritative information, consult the original paper.
Corrections welcome, if I’ve misunderstood something technical, let me know.